
Đây là phần 2 của loạt bài Giới thiệu về phép nhúng từ. Mọi người có thể xem lại phần 1 ở đây.
Phần 1 đã giải thích cho chúng ta hiểu phép nhúng từ là gì và công năng của nó, cùng với 2 mô hình nhúng từ cơ bản là BoW và TF-IDF. Ở phần 2 này, chúng ta sẽ giới thiệu tiếp các phép nhúng từ phức tạp hơn, xuất hiện khi trào lưu học sâu thịnh thành trở lại trong những năm gần đây.
3. Các phép nhúng từ thông dụng (tiếp theo)
c) Word2Vec
Word2Vec (Word to vector) là phương pháp được Google công bố vào năm 2013. Bằng cách thực hiện một tác vụ giả là dự đoán từ nào sẽ xuất trong một phạm vi các từ xung quanh (phạm vi này được gọi là cửa sổ ngữ cảnh – context window), Word2vec sẽ học được ma trận nhúng từ W [V x N], với hai siêu tham số là:
- số hàng V: số lượng từ vựng.
- số cột N: số đặc trưng.
Phương pháp Word2Vec đề xuất 2 cách để huấn luyện ma trận nhúng từ là Túi từ liên tục (Continuous Bag of Words – CBOW) và Skip-gram. Theo quan sát của tác giả, CBOW sẽ có thời gian huấn luyện nhanh hơn. Trong khi đó Skip-gram có thời gian huấn luyện chậm hơn, biểu diễn các từ hiếm gặp tốt hơn.
Skip-gram thường sẽ đi chung với phương pháp Lấy mẫu phủ định (negative sampling) sẽ được đề cập ở bên dưới, đây cũng là cách mà người ta thường sử dụng do có hiệu suất tốt hơn, đặc biệt là khi sử dụng với các tập dữ liệu lớn.
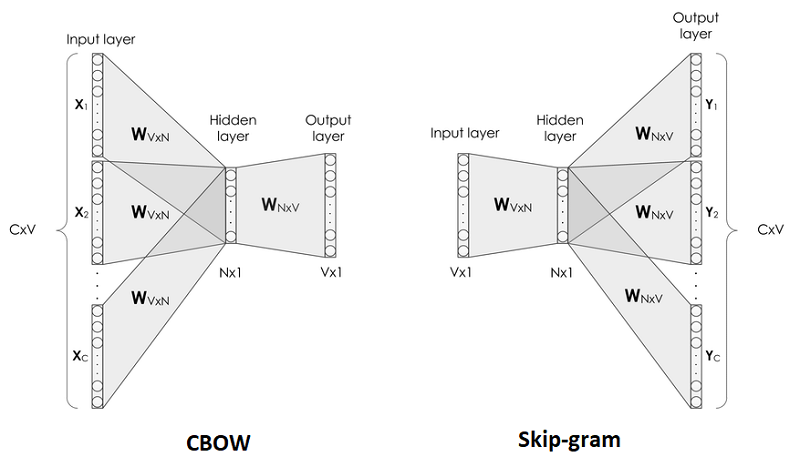
Chú giải:
- Kích thước của cửa sổ ngữ cảnh là C/2. Ví dụ C=2 thì ta sẽ có 5 phần tử (x_1, x_2, x_3, x_4, x_5), với x_3 là phần tử trung tâm, các phần tử còn lại là phần tử ngữ cảnh.
- Số lượng từ vựng là V.
- Số đơn vị ẩn là N.
Sau đây là một ví dụ nhỏ, kèm theo các bước huấn luyện của 2 phương pháp CBOW và Skip-gram để chúng ta dễ hình dung hơn:
- Câu: “Khi cả nhà may áo giáp sắt nhớ sang phố hàn đồng hiệu Á Phi Âu”
- C = 2
- V = 16
- N = 10
Các bước huấn luyện theo CBOW:
Bước 1: Dùng BoW để biến các từ vựng thành vector.
Vocab = [áo, Á, Âu, cả, đồng, giáp, hàn, hiệu, Khi, nhà, may, nhớ, phố, Phi, sang, sắt]
Từ “Khi” sẽ trở thành vector: [0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0]
Từ “cả” trở thành vector: [0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0]
Từ “nhà” trở thành vector: [0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0]
Từ “may” trở thành vector: [0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0]
Từ “áo” trở thành vector: [1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
…
Bước 2: Xác định [đầu vào | đầu ra] của mô hình, mỗi dòng dưới đây là một ô cửa sổ ngữ cảnh.
[Khi, cả, may, áo | nhà]
[cả, nhà, áo, giáp | may]
[nhà, may, giáp, sắt | áo]
[may, áo, sắt, nhớ | giáp]
…
Bước 3: Tính toán & thu lấy ma trận nhúng từ
Đây là một bài toán hồi quy cực đại mềm (softmax regression), mình sẽ không giải thích phần này để bài viết không quá lan man khỏi chủ đề “phép nhúng từ”. Mọi người có thể xem cách giải quyết bài toán chi tiết kèm công thức, code minh họa ở trang machinelearningcoban.

Sau khi huấn luyện hoàn tất, ma trận W[V x N] chính là ma trận nhúng từ mà chúng ta đang tìm.
Từ đây, ví dụ nếu ta muốn lấy vector nhúng từ của chữ “Khi” – [0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0] – đứng thứ 9 trong danh sách từ vựng, ta chỉ cần tra và lấy vector hàng thứ 9 trong ma trận nhúng từ.

Các bước huấn luyện theo Skip-gram:
Bước 1: Tương tự CBOW, Dùng BoW để biến các từ vựng thành vector
Bước 2: Xác định [đầu vào | đầu ra] của mô hình, mỗi dòng dưới đây là một ô cửa sổ
[nhà | Khi], [nhà | cả], [nhà | may], [nhà | áo]
[may| cả], [may| nhà], [may| áo], [may| giáp]
…
Ta có thể nhận thấy với 1 ô cửa sổ, Skip-gram sẽ thu về nhiều mẫu dữ liệu hơn so với CBOW. Lúc này, hàm cực đại mềm (softmax) trở nên rất tốn kém về mặt chi phí (độ phức tạp O(V)) khi nó phải lặp qua toàn bộ V phần tử để tính toán phân phối xác suất.
Do đó người ta đã tìm cách giảm chi phi tính toán bằng cách biến đổi mẫu dữ liệu, đưa về bài toán hồi quy logit (logistic regression) theo 3 bước A, B,C như sau:
Bước A: Khởi tạo 2 ma trận giống nhau từ các vector đơn trội, kích thước là [V x N]:

Bước B: Rút các vector đơn trội từ ma trận tương ứng để hình thành các mẫu dữ liệu

Do mẫu dữ liệu đều có đầu ra là 1, mô hình sẽ không học được gì và luôn dự đoán đúng 100% nên chúng ta sẽ cần phải thêm vào những mẫu dữ liệu thuộc lớp phủ định (đầu ra = 0) bằng cách thêm vào ngẫu nhiên các cặp từ sẽ không xuất hiện gần nhau. Đây chính là kĩ thuật Lấy mẫu phủ định (negative sampling). Thông thường người ta sẽ lấy khoảng [5,20] mẫu phủ định cho mỗi từ cần học.

Đầu vào: các one-hot vector [1 x V]
Đầu ra: 0 hoặc 1
Bước C: Tính toán & thu lấy ma trận nhúng từ
Ta nhân 2 vector với nhau, tính sigmoid, sai số rồi cập nhật tham số tùy theo chiến thuật trượt gradient (gradient descent).

Ma trận [V x N] màu xanh sẽ xem là ma trận nhúng từ mà ta cần tìm.
d) FastText
FastText là thư viện mã nguồn mở do Facebook tạo ra năm 2016, nó hỗ trợ việc huấn luyện phép nhúng từ và phân loại văn bản. FastText được viết bằng ngôn ngữ C++ 11, có thể chạy đa luồng (ngoại trừ thao tác đọc dữ liệu sẽ chạy đơn luồng). Mọi người có thể tham khảo thêm về cú pháp của thư viện, tải các mô hình có sẵn ở trang chính thức.
FastText là một dạng mở rộng của Word2Vec, chỉ khác ở điểm nó tạo thêm các n-gram để học. Ví dụ chữ “đồng”, với n-gram=3 sẽ được tách thành [“<đồng>”,”<đồ”, “đồn”, “ồng”, “ng>”]. Dấu “<“, “>” dùng để phân biệt các n-gram với các từ hoàn chỉnh như “<đồn>”!=”đồn”. Sau khi huấn luyện xong, vector nhúng từ của chữ “đồng” sẽ là tổng của các vector nhúng từ [ “<đồng>”,”<đồ”, “đồn”, “ồng”, “ng>”], nhân với vector của “đồng”.
Nhờ việc tách thành n-gram như vầy mà ta có thể tạo ra được vector nhúng từ của các từ chưa từng xuất hiện trong bước huấn luyện bằng cách cộng các vector n-gram có sẵn lại.
e) GloVe
GloVe (Global Vectors) là thuật toán học phép nhúng từ do đại học Stanfordcông bố vào năm 2014. Ý tưởng chính của GloVe là từ việc quan sát thấy rằng những từ có cùng ý nghĩa hoặc mối quan hệ gần gũi sẽ có xác suất xuất hiện đồng thời cao hơn.

Từ bảng trên, ta có thể thấy xác suất xuất hiện gần nhau của cặp từ [“băng”, “rắn”] cao hơn 2.8 lần khi so với xác suất của cặp từ [“băng”, “khí”]. Hay xác suất của cặp từ [“băng”, “áo”] rất thấp.
Điều này phù hợp với các quan điểm như “băng là thể rắn”, “băng trái ngược với khí”, “băng không liên quan tới áo quần”.
Do đó, mục tiêu của GloVe là học ra các vector từ ngữ để tích vô hướng của chúng sẽ bằng xác suất xuất hiện đồng thời của chúng trong tập dữ liệu, với kì vọng sẽ phù hợp với các quan điểm thông thường.
Các bước huấn luyện của GloVe:
Bước 1: Xây dựng ma trận xuất hiện đồng thời X (co-occurrence matrix)

X_ij là số lần mà từ j sẽ xuất hiện trong ngữ cảnh của i, hay nói đơn giản hơn là số lần mà i và j cùng xuất hiện gần nhau. Thuật toán GloVe chọn ngữ cảnh dựa trên cửa sổ ngữ cảnh nên kết quả thu được là một ma trận vuông đối xứng qua đường chéo chính.
VD: Số lần từ “là” và “sinh” cùng xuất hiện gần nhau (count(là | sinh)) = 2 do từ “là” xuất hiện trong phạm vi cửa sổ bằng 2 ở 2 câu “Tôi là học sinh” và “Tôi là sinh viên”.
Bước 2: Chuyển thành ma trận log xác suất xuất hiện đồng thời P


VD: Số từ xuất hiện trong ngữ cảnh của từ “Tôi” bằng 6, gồm [“là”, “học”, “là”, “sinh”, “không”, “phải”]
Bước 3: Khởi tạo 2 ma trận co kích thước [V x N] và [N x V]

Mục tiêu của chúng ta là tối ưu hóa để tạo ra 2 ma trận word_vector[V x N] và context_vector[N x V] sao cho tích vô hướng của chúng sẽ bằng P[V x V].
Bước 4: Tính toán và thu lấy ma trận nhúng từ
Đây là dạng bài toán hồi quy, ta sẽ giải quyết với hàm mất mát (loss function) do nhóm tác giả đưa ra bên dưới và các chiến thuật trượt gradient tự chọn. Nếu ai quan tâm đến cách suy ra được công thức hàm này thì có thể tham khảo qua bài báo gốc.

Kểt quả cuối cùng mà chúng ta thu được là ma trận nhúng từ word_vector [V x N].
Code ví dụ
Đây là code ví dụ trên Google Colab, bao gồm các thao tác:
+ Chuyển đầu vào về định dạng mà gensim yêu cầu.
+ Xây dựng kho từ vựng.
+ Huấn luyện mô hình với các siêu tham số.
+ Lưu/nạp mô hình.
+ Huấn luyện đầu vào mới từ mô hình có sẵn.
Đối với Glove, ta có một nhược điểm là không thể nạp mô hình có sẵn rồi tiếp tục huấn luyện với dữ liệu mới.
Kết thúc phần 2, mình đã giới thiệu được 5 trong sốcác phương pháp nhúng từ phổ biến nhất hiện nay. Chúng đã được cộng đồng học máy sử dụng nhiều năm qua nên có rất nhiều các mô hình được huấn luyện sẵn thuộc nhiều ngôn ngữ, thư viện hỗ trợ, thậm chí là mã nguồn mở ứng dụng các phương pháp này để giải quyết nhiều tác vụ. Do đó, chúng sẽ là lựa chọn sáng giá nếu bạn muốn giải quyết những bài toán học máy đơn giản và nhỏ, hoặc dùng làm thước đo cơ sở trước khi cân nhắc những phương pháp nhúng từ cao cấp hơn.
Trên thực tế thì mình thấy có nhiều doanh nghiệp VN cũng chỉ ứng dụng được đến 5 phương pháp này do tập dữ liệu còn nhỏ, chưa có đủ nguồn lực để tính toán học sâu,…
Trong phần 3 tới, mình sẽ tóm tắt thêm vài phương pháp nhúng từ xuất hiện trong 2 năm trở lại đây như ELMo, BERT, XLNet và ERNIE. Đây là những phương pháp đòi hỏi rất nhiều dữ liệu huấn luyện, cũng như là nguồn lực tính toán lớn (Titan X, GTX 1080 hay TPU có 64gb ram). Đổi lại, hiệu suất của chúng rất cao, một vài tác vụ đã làm tốt hơn cả con người như Trả lời câu hỏi (question answering SQuAD 2.0), đánh giá hiểu biết ngôn ngữ tổng quát (General Language Understanding Evaluation – GLUE).
